(SeaPRwire) – التقسيم الهرمي الذكي هو التحضير المثالي للبيانات لترابطات قواعد البيانات المتجهة
برلين، برلين، 16 مارس 2026 — POMA AI، شركة معلوماتية للوثائق مقرها برلين، أصدرت اليوم POMA-OfficeQA، معيار مفتوح المصدر يُظهر أن تقسيم الوثائق القائم على الهيكل الخاص بها يقلل من تكاليف استرجاع RAG بنسبة 77٪ مقارنة بكل من تقسيم النص البسيط وطريقة استخراج العناصر لـ Unstructured.io.
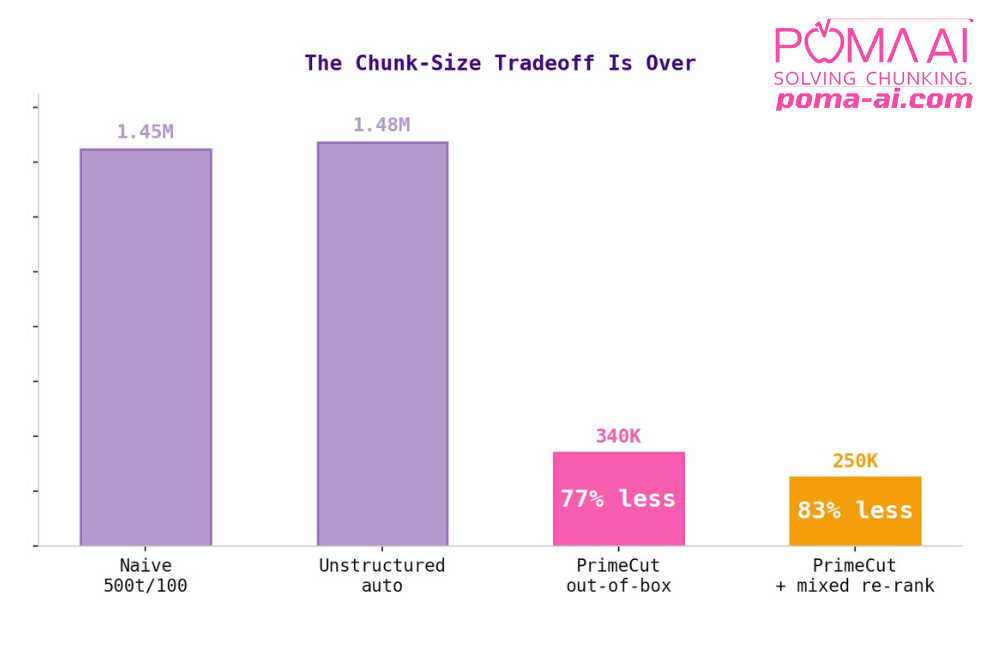
بشكل افتراضي، يستخدم POMA PrimeCut 77٪ أقل من الرموز مقارنة بالنماذج التقليدية. ترتفع هذه الأرقام إلى 83٪ عند الاستخدام في تكوينات مخصصة.
“كل نظام RAG قيد الانتاج اليوم يفقد المعلومات قبل أن يراه النموذج حتى،” قال د. أليكساندر كيهم، مؤسس ومح müdير التنفيذ لـ POMA AI. “لقد قامت الصناعة بتحسين الـ embeddings، والمرتبعون újra، وهندسة التعليمات، لكن طبقة الالتهام (ingestion layer) هي حيث تنشأ معظم فشلات الاسترجاع في الواقع. هذا المعيار يُقسى ما شعره المطوّرون بدقة فطرية: التقسيم القائم على الهيكل هو الأساس الذي يجعل كل شيء اللاحق يعمل فعلاً.”
تم اختبار المعيار الكامل، المتوافر على GitHub، ثلاث استراتيجيات تقسيم الوثائق لـ Retrieval-Augmented Generation (RAG) باستخدام embeddings متطابقة، ومنطق استرجاع متطابق، و20 سؤال بحث في الجدول عبر 14 بلتينًا لوزارة الخزانة الأمريكية (~2150 صفحة). قاس الاختبار قدرة كل طريقة على استرجاع جميع الأدلة اللازمة لإجابة الأسئلة الواقعية بشكل صحيح، مع المقياس (استرجاع السياق) الذي يحدد الحد الأدنى من ميزانية الرموز التي يحتاجها نظام الاسترجاع لضمان توافر جميع الأدلة في السياق المسترجع.
أظهرت النتائج أن تقسيم POMA الهرمي —الذي يحافظ على هيكل الوثيقة بما في ذلك رؤوس الجداول، وهيرارشية الأقسام، والعلاقات الدلالية بين عناصر المحتوى— أطلقت 77٪ أقل من الرموز لتحقيق 100٪ استرجاع السياق:
- الخط الأساسي (تقسيم بسيط بـ 500 رمز، تداخل 100): 1.45 مليون
- Unstructured.io (استخراج العناصر: 1.48 مليون
- POMA AI (قائم على الهيكل): 340 ألف
استخدمت جميع الطرق نموذج text-embedding-3-large من OpenAI للترابطات ومماثلته الكوسينية لتصنيف الاسترجاع. تم تحديد الحقيقة الأساسية باستخدام مؤشرات مقطع دقيقة تم التحقق منها مقابل الوثائق المصدرية — مما يُزيل النتائج المُضادة الخاطئة من التطابقات الرقمية العرضية. تم تضمين فقط الأسئلة التي يمكن الإجابة عليها بواسطة جميع الطرق الثلاث، مما يضمن مقارنة عادلة. تم استبعاد الأسئلة حيث واجهت أي طريقة فشلات في الاستخراج (أخطاء OCR، قيم مفقودة).
“ما أثقنا في POMA هو الصرامة الهندسية وراء فكرة بدية تبدو بسيطة،” قال تيل فيدا، مؤسس شريك لـ AdBlock ومستثمر ومستشار لـ POMA AI. “ذهبوا إلى طبقة الالتهام (ingestion layer)، وهي الجزء من خط الأنابيب الذي يفترض الجميع أنه مشكلة محلولة. يُظهر هذا المعيار أن هذا ليس صحيحًا. خفض الرموز بنسبة 77٪ يغير إقتصاد تشغيل RAG على نطاق المؤسسة. هذه هي نوع الميزة الهيكلية التي نبحث عنها.”
حول POMA AI: POMA AI هي شركة معلوماتية للوثائق مقرها برلين تقوم ببناء البنية التحتية لأنظمة RAG للمؤسسات. تقوم تقنيتها الأساسية بتحويل الوثائق المعقدة إلى مقاطع متماسكة دلالياً جاهزة للبحث المتجهي والاستهلاك LLM. تُعالج واجهة برمجة التطبيقات (API) لـ POMA الوثائق في مكالمة واحدة وتُخرج كلاً من المقاطع الدقيقة ومجموعات المقاطع المجمعة، متوافقة مع أي نموذج ترابط ومخزن متجهي. تتوافر النسخة التجريبية المجانية على موقع الويب لـ POMA AI. يمكن العثور على معلومات إضافية عن POMA AI على LinkedIn أو X (تويتر).

أظهرت ترابطات POMA PrimeCut القائمة على الهيكل تحسناً بنسبة 119 ضعف مقارنة بالترابطات التي تعتمد على السياق فقط.
استفسارات الصحافة
فلوريان أثينز
fa [at] poma-ai.com
https://poma-ai.com
يتم توفير المقال من قبل مزود محتوى خارجي. لا تقدم SeaPRwire (https://www.seaprwire.com/) أي ضمانات أو تصريحات فيما يتعلق بذلك.
القطاعات: العنوان الرئيسي، الأخبار اليومية
يوفر SeaPRwire تداول بيانات صحفية في الوقت الفعلي للشركات والمؤسسات، مع الوصول إلى أكثر من 6500 متجر إعلامي و 86000 محرر وصحفي، و3.5 مليون سطح مكتب احترافي في 90 دولة. يدعم SeaPRwire توزيع البيانات الصحفية باللغات الإنجليزية والكورية واليابانية والعربية والصينية المبسطة والصينية التقليدية والفيتنامية والتايلندية والإندونيسية والملايو والألمانية والروسية والفرنسية والإسبانية والبرتغالية ولغات أخرى.